-

阿里云waf开发测试策略与回滚机制设计降低上线风险确保业务稳定
2026/5/25 -
安全工程师指南waf锐速云原理与常见部署拓扑对比分析
2026/7/4 -

阿里云waf配置教程结合API网关和云盾实现全站安全防护方案
2026/5/21 -

网宿云waf拦截是什么规则自定义与日志审计指南
2026/4/15 -

华为云waf多少钱详解功能差异与性价比比较指南
2026/4/26 -

云waf 部署全流程详解 从评估到上线的实操手册
2026/3/11
阿里云waf出问题排查实战案例分享与配置优化建议
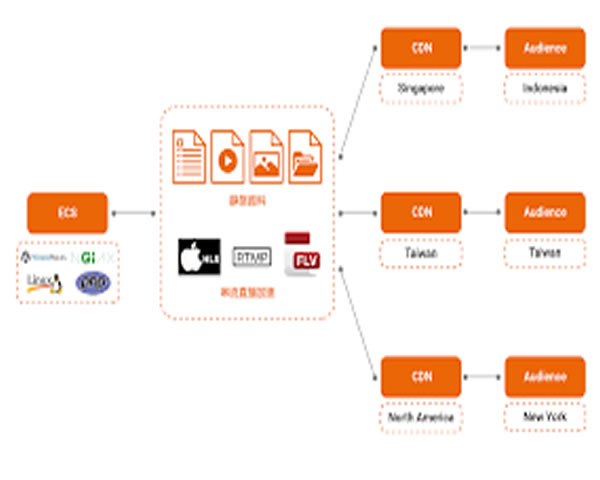
引言:本文基于阿里云waf出问题排查实战案例分享与配置优化建议,旨在为安全运维和平台工程师提供一套系统化的排查思路与可落地的配置改进方向,帮助快速恢复业务并减少复发。
问题背景与排查流程概览
在遭遇业务异常或误拦截时,首先确认影响范围、时间窗与业务版本。阿里云waf出问题排查实战案例分享建议采用“确认-收集-分析-验证-处置”的闭环流程,分层定位前端规则、回源策略或网络链路问题。
常见故障类型与表现
常见故障包括误拦截正常请求、规则放行漏报、性能抖动以及证书或回源鉴权异常。阿里云waf出问题排查实战案例分享显示,多数问题可从最近规则变更或流量异常入手排查。
日志分析实战:如何定位请求异常
日志是排查核心;优先查看waf access log、alarm log及回源日志,按请求ID或时间戳关联。阿里云waf出问题排查实战案例分享中,按URI、User-Agent与规则ID过滤能快速定位命中规则与触发条件。
规则与策略调整要点
调整规则需遵循最小权限原则:先临时放行疑似误拦请求,再细化规则或添加例外。阿里云waf出问题排查实战案例分享建议使用分阶段下发、灰度与回滚机制,避免一次性全量生效带来风险。
配置优化建议(性能与安全平衡)
优化配置包括合理启用高频规则、采用速率限制防护热点接口、配置回源检测与连接池优化。阿里云waf出问题排查实战案例分享强调在保证安全的前提下,通过规则分级与缓存策略降低误拦与延迟。
自动化与监控建议
建议建立基于告警策略的自动化响应:异常流量告警触发流量快照与规则回退预案。阿里云waf出问题排查实战案例分享表明,结合Prometheus/云监控可实现可视化趋势与告警抑制,提高处置效率。
回滚与演练要点
回滚流程要简洁且可验证:保存变更记录、定义回滚触发条件并预演。阿里云waf出问题排查实战案例分享建议定期进行演练,验证规则生效与业务兼容性,避免变更后出现不可预料的服务中断。
总结与建议
总结:面对阿里云waf出问题排查实战案例分享的教训,应建立标准化排查流程、完善日志链路、分级管理规则并推进监控自动化。持续优化规则与演练回滚是降低复发概率的核心措施,建议结合业务节奏制定变更窗口与灰度策略。